Thursday, November 14, 2013
Thrive School - learn to thrive: Hive Getting Started
Thrive School - learn to thrive: Hive Getting Started: In my previous post, we saw how we can execute MapReduce jobs using Java. Java is most flexible and powerful method for doing all MapReduce...
Tuesday, November 12, 2013
Thrive School - learn to thrive: Executing Java MapReduce Program
Thrive School - learn to thrive: Executing Java MapReduce Program: In my previous post, we explored MapReduce concept using a bash shell script. In this post we will compile and execute a MapReduce program...
Thrive School - learn to thrive: Geting a portable hadoop environment
Thrive School - learn to thrive: Geting a portable hadoop environment: Before we start learning individual components of hadoop ecosystem, it is good to get your portable hadoop environment. There are various o...
Wednesday, November 6, 2013
DATA SCIENCE RESOURCES : Data Science
Resources : Data Science
Data Science is an inherently multidisciplinary field that requires a myriadof skills to be a proficient practitioner. The necessary curriculum has not fit into traditional course offerings, but asawareness of theneed for individuals who have such abilities is growing, we are seeing universities and private companies creating custom classes.
- Books
- An Introduction to Data Science: The companion textbook to Syracuse University’s flagship course for their new Data Science program.
- Courses
- UC Berkeley: Introduction to Data Science: A course taught by Jeff Hammerbacher and Mike Franklin that highlights each of the varied skills that a Data Scientist must be proficient with.
- CouHow to Process, Analyze and Visualize Data: A lab oriented course that teaches you the entire pipeline of data science; from acquiring datasets and analyzing them at scale to effectively visualizing the results.
- CMCoursera: Introduction to Data Science: A tour of the basic techniques for Data Science including SQL and NoSQL databases, MapReduce on Hadoop, ML algorithms, and data visualization.
- Columbia: Introduction to Data Science: A very comprehensive course that covers all aspects of data science, with an humanistic treatment of the field.
- Columbia: Applied Data Science (with book): Another Columbia course — teaches applied software development fundamentals using real data, targeted towards people with mathematical backgrounds.
- Coursera: Data Analysis (with notes and lectures): An applied statistics course that covers algorithms and techniques for analyzing data and interpreting the results to communicate your findings.
- Kaggle: Getting Started with Python for Data Science: A guided tour of setting up a development environment, an introduction to making your first competition submission, and validating your results.
- http://ischool.syr.edu/future/cas/applieddatasciencemooc.aspx
Resources : Others
- Data Beta: Professor Joe Hellerstein’s blog about education, computing, and data.
- Dataists: Hilary Mason and Vince Buffalo’s old blog that has a wealth of information and resources about the field and practice of data science
- Five Thirty Eight: Nate Silver’s famous NYT blog where he discusses predictive modeling and political forecasts.
- grep alex: Alex Holmes’s blog about distributed computing and the intricacies of Hadoop.
- Data Science 101: One man’s personal journey to becoming a data scientist (with plenty of resources)
- no free hunch: Kaggle’s blog about the practice of data science and its competition highlights.
- Berkeley: Introduction to Data Science: One of the most comprehensive lists of resources about all things data science.
- Cloudera: New to Data Science: Resources about data science from Cloudera’s introduction to data science course/certification.
- Kaggle: Tutorials: A set of tutorials, books, courses, and competitions for statistics, data analysis, and machine learning.
- http://dataiap.github.io/dataiap
- http://cs229.stanford.edu/materials.html
- http://www-stat.stanford.edu/~naras/stat290/Stat290_Website/Stat_290.html
- http://see.stanford.edu/see/lecturelist.aspx?coll=348ca38a-3a6d-4052-937d-cb017338d7b1
- http://www.ischool.berkeley.edu/courses/i290-abdt
- http://hackershelf.com/topic/machine-learning/
- http://www.e-booksdirectory.com/listing.php?category=284
- http://www.intechopen.com/books/machine-learning
- http://pages.cs.wisc.edu/~shavlik/cs760.html
- http://www.realtechsupport.org/UB/MRIII/papers/MachineLearning/Alppaydin_MachineLearning_2010.pdf
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-867-machine-learning-fall-2006/index.html
- http://www3.nd.edu/~steve/Rcourse/Rnotes.html
- http://alex.smola.org/teaching/cmu2013-10-701/
- http://www.cmpe.boun.edu.tr/~ethem/i2ml2e/
- http://courses.ischool.berkeley.edu/i296a-dsa/s12/
- http://datascienc.es/spring-2011-course/
DATA SCIENCE RESOURCES: Large Scale Computations
Large Scale Computations
When you start operating with data at the scale of the web, the fundamental approach and process of analysis must change. To combat the ever increasing amount of data, Google developed theMapReduce paradigm. This programming model has become the de facto standard for large scale batch processing since the release of ApacheHadoop in 2007, the open-source MapReduce framework
- Books
- Mining Massive Datasets:Mining Massive Datasets: Stanford course resources on large scale machine learning and MapReduce with accompanyingbook.
- Data-Intensive Text Processing with MapReduce:Data-Intensive Text Processing with MapReduce: An introduction to algorithms for the indexing and processing of text that teaches you to “think in MapReduce.”
- Hadoop: The Definitive Guide: The most thorough treatment of the Hadoop framework, a great tutorial and reference alike.
- Programming Pig: An introduction to the Pig framework for programming data flows on Hadoop.
- Courses
- UC Berkeley: Analyzing Big Data with Twitter: A course — taught in close collaboration with Twitter — that focuses on the tools and algorithms for data analysis as applied to Twitter microblog data (with project based curriculum).
- Coursera: Web Intelligence and Big Data: An introduction to dealing with large quantities of data from the web; how the tools and techniques for acquiring, manipulating, querying, and analyzing data change at scale.
- CMU: Machine Learning with Large Datasets: A course on scaling machine learning algorithms on Hadoop to handle massive datasets.
- U of Chicago: Large Scale Learning: A treatment of handling large datasets through dimensionality reduction, classification, feature parametrization, and efficient data structures.
- UC Berkeley: Scalable Machine Learning: A broad introduction to the systems, algorithms, models, and optimizations necessary at scale.
DATA SCIENCE RESOURCES: Visualization
Visualization
- Books
- Tufte: The Visual Display of Quantitative Information:Not freely available, but perhaps the most influential text for the subject of data visualization. A classic that defined the field.
- Courses
- UC Berkeley: Visualization: UC Berkeley: Visualization: Graduate class on the techniques and algorithms for creating effective visualizations.
- Rice: Data Visualization: Rice: Data Visualization: A treatment of data visualization and how to meaningfully present information from the perspective of Statistics.
- Harvard: Introduction to Computing, Modeling, and Visualization: Connects the concepts of computing with data to the process of interactively visualizing results.
- School of Data: From Data to Diagrams: A gentle introduction to plotting and charting data, with exercises.
- Predictive Analytics: Overview and Data visualization: An introduction to the process of predictive modeling, and a treatment of the visualization of its results.
- Tools
- D3.js: Data-Driven Documents — Declarative manipulation of DOM elements with data dependent functions (withPython port ).
- Vega: A visualization grammer built on top of D3 for declarative visualizations in JSON. Released by the dream team atTrifacta, it provides a higher level abstraction than D3 for creating “ or SVG based graphics.
- Rickshaw: A charting library built on top of D3 with a focus on interactive time series graphs.
- modest maps: A lightweight library with a simple interface for working with maps in the browser (with ports to multiple languages).
- Chart.js: Very simple (only six charts) HTML5 “ based plotting library with beautiful styling and animation.
DATA SCIENCE RESOURCES: Statistics
Statistics
- Books
- O’Reilly: Think Stats:An introduction to Probability and Statistics for Python programmers.
- Introduction to Probability: Textbook for Berkeley’s Stats 134 class, an introductory treatment of probability with complementary exercises.
- Lecture notes for Introduction to Probability: Compiled lecture notes of above textbook, complete with exercises.
- OpenIntro: Statistics: Introductory text book with supplementary exercises and labs in an online portal.
- Think Bayes: An simple introduction to Bayesian Statistics with Python code examples.
- Courses
- edx:Introduction to Statistics: A basic introductory statistics course.
- Coursera: Statistics one : A first course of Statistics from Andrew Conway of Princeton University
- Coursera: Statistics, Making sense of Data: A applied Statistics course that teaches the complete pipeline of statistical analysis.
- MIT:Statistical Thinking and Data Analysis: Introduction to probability, sampling, regression, common distributions, and inference.
- Khan Academy’s Statistics : A wonderful introduction to all things statistics in a very lucid manner .
DATA SCIENCE RESOURCES: Machine Learning and Algorithms
Machine Learning and Algorithms
- Books
- A first encounter with Machine Learning: An introduction to machine learning concepts focusing on the intuition and explanation behind whythey work.
- A Programmer’s Guide to Data Mining: A web based book complete with code samples (in Python) and exercises.
- Data Structures and Algorithms: An introduction to computer science with code examples in Python — covers algorithm analysis, data structures, sorting algorithms, and object oriented design.
- An Introduction to Data Mining: An interactive Decision Tree guide (with hyperlinked lectures) to learning data mining and ML.
- Elements of Statistical Learning: One of the most comprehensive treatments of data mining and ML, often used as a university textbook.
- An Introduction to Information Retrieval: Textbook from a Stanford course on NLP and information retrieval with sections on text classification, clustering, indexing, and web crawling.
- Courses
- Coursera: Machine Learning: Stanford’s famous machine learning course taught by Andrew Ng.
- Coursera: Computational Methods for Data Analysis: Statistical methods and data analysis applied to physical, engineering, and biological sciences.
- MIT: Data Mining: MIT: Data Mining: An introduction to the techniques of data mining and how to apply ML algorithms to garner insights.
- edx: Introduction to Artificial Intelligence: The first half of Berkeley’s popular AI course that teaches you to build autonomous agents to efficiently make decisions in stochastic and adversarial settings.
- edx: Introduction to Computer Science and Programming: MIT’s introductory course to the theory and application of Computer Science.
Monday, October 7, 2013
Tools for Social Network Analysis
Here are the list of open-source tools for analyzing social networks
Gephi (http://gephi.org/). Visualization and basic network metrics.
NetLogo (modeling network dynamics)
iGraph (for programming)
Pajek (http://pajek.imfm.si/doku.php). Very extensive functionality via drop-down menus. Open-Source. Works only on windows.
NodeXL (http://nodexl.codeplex.com/). SNA integrated into Excel. Windows-only. Free. In beta.
NetworkX (http://networkx.lanl.gov/). Extensive functionality. Open Source. Scales to large networks by taking advantage of existing C, Fortran libs.
SNA Package for R (http://cran.r-project.org/web/packages/sna/index.html). Extensive, statistics-heavy functionality
Social Network Image Animator (http://www.stanford.edu/group/sonia/)
Books:
Exploratory Social Network Analysis with Pajek (Structural Analysis in the Social Sciences)
Social Network Analysis: History, Theory and Methodology
Understanding Social Networks: Theories, Concepts, and Findings
Gephi (http://gephi.org/). Visualization and basic network metrics.
NetLogo (modeling network dynamics)
iGraph (for programming)
Pajek (http://pajek.imfm.si/doku.php). Very extensive functionality via drop-down menus. Open-Source. Works only on windows.
NodeXL (http://nodexl.codeplex.com/). SNA integrated into Excel. Windows-only. Free. In beta.
NetworkX (http://networkx.lanl.gov/). Extensive functionality. Open Source. Scales to large networks by taking advantage of existing C, Fortran libs.
SNA Package for R (http://cran.r-project.org/web/packages/sna/index.html). Extensive, statistics-heavy functionality
Social Network Image Animator (http://www.stanford.edu/group/sonia/)
Books:
Exploratory Social Network Analysis with Pajek (Structural Analysis in the Social Sciences)
Social Network Analysis: History, Theory and Methodology
Understanding Social Networks: Theories, Concepts, and Findings
Thursday, October 3, 2013

Friday, September 27, 2013

Tuesday, June 18, 2013
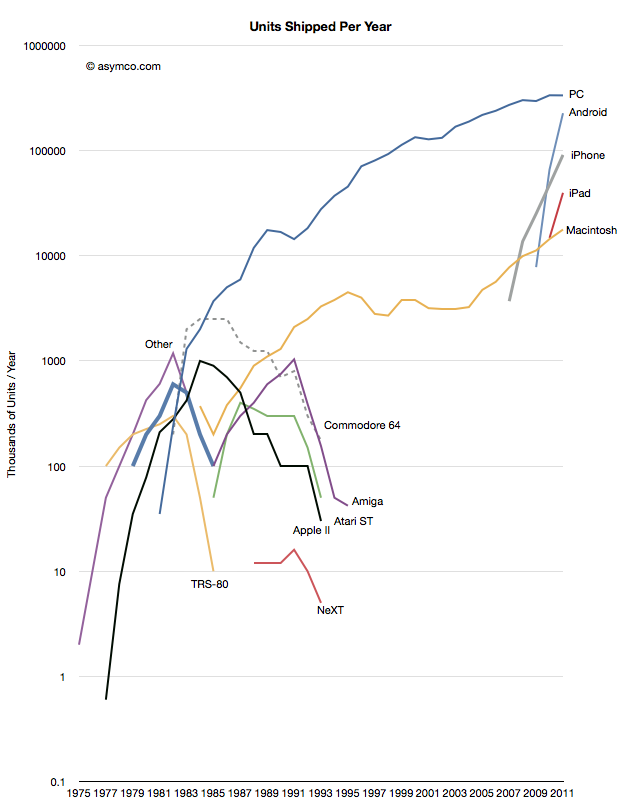
Monday, June 3, 2013

Tuesday, April 16, 2013


Monday, March 18, 2013
Hadoop Qs for certification
JobTracker is the daemon service for submitting and tracking MapReduce jobs in Hadoop. There is only One Job Tracker process run on any hadoop cluster. Job Tracker runs on its own JVM process. In a typical production cluster its run on a separate machine. Each slave node is configured with job tracker node location. The JobTracker is single point of failure for the Hadoop MapReduce service. If it goes down, all running jobs are halted. JobTracker in Hadoop performs following actions: (from Hadoop Wiki)
§ Client applications submit jobs to the Job tracker.
§ The JobTracker talks to the NameNode to determine the location of the data
§ The JobTracker locates TaskTracker nodes with available slots at or near the data
§ The JobTracker submits the work to the chosen TaskTracker nodes.
§ The TaskTracker nodes are monitored. If they do not submit heartbeat signals often enough, they are deemed to have failed and the work is scheduled on a different TaskTracker.
§ A TaskTracker will notify the JobTracker when a task fails. The JobTracker decides what to do then: it may resubmit the job elsewhere, it may mark that specific record as something to avoid, and it may even blacklist the TaskTracker as unreliable.
§ When the work is completed, the JobTracker updates its status.
§ Client applications can poll the JobTracker for information.
The TaskTracker send out heartbeat messages to the JobTracker, usually every few minutes, to reassure the JobTracker that it is still alive. These messages also inform the JobTracker of the number of available slots, so the JobTracker can stay up to date with where in the cluster work can be delegated. When the JobTracker tries to find somewhere to schedule a task within the MapReduce operations, it first looks for an empty slot on the same server that hosts the DataNode containing the data, and if not, it looks for an empty slot on a machine in the same rack.
A TaskTracker is a slave node daemon in the cluster that accepts tasks (Map, Reduce and Shuffle operations) from a JobTracker. There is only One Task Tracker process run on any hadoop slave node. Task Tracker runs on its own JVM process. Every TaskTracker is configured with a set of slots. These indicate the number of tasks that it can accept. The TaskTracker starts a separate JVM processes to do the actual work (called as Task Instance) this is to ensure that process failure does not take down the task tracker. The TaskTracker monitors these task instances, capturing the output and exit codes. When the Task instances finish, successfully or not, the task tracker notifies the JobTracker. The TaskTrackers also send out heartbeat messages to the JobTracker, usually every few minutes, to reassure the JobTracker that it is still alive. These messages also inform the JobTracker of the number of available slots, so the JobTracker can stay up to date with where in the cluster work can be delegated.
Task instances are the actual MapReduce jobs which are run on each slave node. The TaskTracker starts a separate JVM processes to do the actual work (called as Task Instance) this is to ensure that process failure does not take down the task tracker. Each Task Instance runs on its own JVM process. There can be multiple processes of task instance running on a slave node. This is based on the number of slots configured on task tracker. By default a new task instance JVM process is spawned for a task.
Hadoop is comprised of five separate daemons. Each of these daemons runs in its own JVM.
Following 3 Daemons run on Master nodes
§ NameNode - This daemon stores and maintains the metadata for HDFS.
§ Secondary NameNode - Performs housekeeping functions for the NameNode.
§ JobTracker - Manages MapReduce jobs, distributes individual tasks to machines running the Task Tracker.
Following 2 Daemons run on each Slave nodes
§ DataNode – Stores actual HDFS data blocks.
§ TaskTracker - Responsible for instantiating and monitoring individual Map and Reduce tasks.
6. What is configuration of a typical slave node on Hadoop cluster? How many JVMs run on a slave node?
§ Single instance of a Task Tracker is run on each Slave node. Task tracker is run as a separate JVM process.
§ Single instance of a DataNode daemon is run on each Slave node. DataNode daemon is run as a separate JVM process.
§ One or Multiple instances of Task Instance is run on each slave node. Each task instance is run as a separate JVM process. The number of Task instances can be controlled by configuration. Typically a high end machine is configured to run more task instances.
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. Following are differences between HDFS and NAS
- In HDFS Data Blocks are distributed across local drives of all machines in a cluster. Whereas in NAS data is stored on dedicated hardware.
- HDFS is designed to work with MapReduce System, since computations are moved to data. NAS is not suitable for MapReduce since data is stored separately from the computations.
§ HDFS runs on a cluster of machines and provides redundancy using a replication protocol. Whereas NAS is provided by a single machine therefore does not provide data redundancy.
NameNode periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode. When NameNode notices that it has not received a heartbeat message from a data node after a certain amount of time, the data node is marked as dead. Since blocks will be under replicated the system begins replicating the blocks that were stored on the dead datanode. The NameNode Orchestrates the replication of data blocks from one datanode to another. The replication data transfer happens directly between datanodes and the data never passes through the namenode.
9. Does MapReduce programming model provide a way for reducers to communicate with each other? In a MapReduce job can a reducer communicate with another reducer?
Nope, MapReduce programming model does not allow reducers to communicate with each other. Reducers run in isolation.
Yes, setting the number of reducers to zero is a valid configuration in Hadoop. When you set the reducers to zero no reducers will be executed, and the output of each mapper will be stored to a separate file on HDFS. [This is different from the condition when reducers are set to a number greater than zero and the Mappers output (intermediate data) is written to the Local file system (NOT HDFS) of each mapper slave node.]
The mapper output (intermediate data) is stored on the Local file system (NOT HDFS) of each individual mapper nodes. This is typically a temporary directory location which can be setup in config by the hadoop administrator. The intermediate data is cleaned up after the Hadoop Job completes.
12. What are combiners? When should I use a combiner in my MapReduce Job? Combiners are used to increase the efficiency of a MapReduce program. They are used to aggregate intermediate map output locally on individual mapper outputs. Combiners can help you reduce the amount of data that needs to be transferred across to the reducers. You can use your reducer code as a combiner if the operation performed is commutative and associative. The execution of combiner is not guaranteed. Hadoop may or may not execute a combiner. Also, if required it may execute it more than 1 times. Therefore your MapReduce jobs should not depend on the combiner’s execution.
§ org.apache.hadoop.io.Writable is a Java interface. Any key or value type in the Hadoop Map-Reduce framework implements this interface. Implementations typically implement a static read (DataInput) method which constructs a new instance, calls readFields (DataInput) and returns the instance.
§ org.apache.hadoop.io.WritableComparable is a Java interface. Any type which is to be used as a key in the Hadoop Map-Reduce framework should implement this interface. WritableComparable objects can be compared to each other using Comparators.
§ The Key must implement the org.apache.hadoop.io.WritableComparable interface.
§ The value must implement the org.apache.hadoop.io.Writable interface.
§ org.apache.hadoop.mapred.lib.IdentityMapper Implements the identity function, mapping inputs directly to outputs. If MapReduce programmers do not set the Mapper Class using JobConf.setMapperClass then IdentityMapper.class is used as a default value.
§ org.apache.hadoop.mapred.lib.IdentityReducer Performs no reduction, writing all input values directly to the output. If MapReduce programmers do not set the Reducer Class using JobConf.setReducerClass then IdentityReducer.class is used as a default value.
16. What is the meaning of speculative execution in Hadoop? Why is it important? Speculative execution is a way of coping with individual Machine performance. In large clusters where hundreds or thousands of machines are involved there may be machines which are not performing as fast as others. This may result in delays in a full job due to only one machine not performing well. To avoid this, speculative execution in hadoop can run multiple copies of same map or reduce task on different slave nodes. The results from first node to finish are used.
In a MapReduce job reducers do not start executing the reduce method until the all Map jobs have completed. Reducers start copying intermediate key-value pairs from the mappers as soon as they are available. The programmer defined reduce method is called only after all the mappers have finished.
18. If reducers do not start before all mappers finish then why does the progress on MapReduce job shows something like Map (50%) Reduce (10%)? Why reducer’s progress percentage is displayed when mapper is not finished yet?
Reducers start copying intermediate key-value pairs from the mappers as soon as they are available. The progress calculation also takes in account the processing of data transfer which is done by reduce process, therefore the reduce progress starts showing up as soon as any intermediate key-value pair for a mapper is available to be transferred to reducer. Though the reducer progress is updated still the programmer defined reduce method is called only after all the mappers have finished.
HDFS, the Hadoop Distributed File System, is responsible for storing huge data on the cluster. This is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant.
§ HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware.
§ HDFS provides high throughput access to application data and is suitable for applications that have large data sets.
§ HDFS is designed to support very large files. Applications that are compatible with HDFS are those that deal with large data sets. These applications write their data only once but they read it one or more times and require these reads to be satisfied at streaming speeds. HDFS supports write-once-read-many semantics on files.
In HDFS data is split into blocks and distributed across multiple nodes in the cluster. Each block is typically 64Mb or 128Mb in size. Each block is replicated multiple times. Default is to replicate each block three times. Replicas are stored on different nodes. HDFS utilizes the local file system to store each HDFS block as a separate file. HDFS Block size cannot be compared with the traditional file system block size.
The NameNode is the centerpiece of an HDFS file system. It keeps the directory tree of all files in the file system, and tracks where across the cluster the file data is kept. It does not store the data of these files itself. There is only One NameNode process run on any hadoop cluster. NameNode runs on its own JVM process. In a typical production cluster its run on a separate machine. The NameNode is a Single Point of Failure for the HDFS Cluster. When the NameNode goes down, the file system goes offline. Client applications talk to the NameNode whenever they wish to locate a file, or when they want to add/copy/move/delete a file. The NameNode responds the successful requests by returning a list of relevant DataNode servers where the data lives.
22. What is a DataNode? How many instances of DataNode run on a Hadoop Cluster? A DataNode stores data in the Hadoop File System HDFS. There is only One DataNode process run on any hadoop slave node. DataNode runs on its own JVM process. On startup, a DataNode connects to the NameNode. DataNode instances can talk to each other. This is mostly during replicating data.
The Client communication to HDFS happens using Hadoop HDFS API. Client applications talk to the NameNode whenever they wish to locate a file, or when they want to add/copy/move/delete a file on HDFS. The NameNode responds the successful requests by returning a list of relevant DataNode servers where the data lives. Client applications can talk directly to a DataNode, once the NameNode has provided the location of the data.
HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once and have strictly one writer at any time. The NameNode makes all decisions regarding replication of blocks. HDFS uses rack-aware replica placement policy. In default configurations there are total 3 copies of a datablock on HDFS, 2 copies are stored on datanodes on same rack and 3rd copy on a different rack.
These are some other sample questions (don’t have answers) from Cloudera certification site.
25. You use the hadoop fs -put command to add sales.txt to HDFS. This file is small enough that it fits into a single block, which is replicated to three nodes within your cluster. When and how will the cluster handle replication following the failure of one of these nodes?
A. The cluster will make no attempt to re-replicate this block.
B. This block will be immediately re-replicated and all other HDFS operations on the cluster will halt while this is in progress.
C. The block will remain under-replicated until the administrator manually deletes and recreates the file.
D. The file will be re-replicated automatically after the NameNode determines it is under-replicated based on the block reports it receives from the DataNodes.
26. You need to write code to perform a complex calculation that takes several steps. You have decided to chain these jobs together and develop a custom composite class for the key that stores the results of intermediate calculations. Which interface must this key implement?
A. Writable
B. Transferable
C. CompositeSortable
D. WritableComparable
27. You are developing an application that uses a year for the key. Which Hadoop-supplied data type would be most appropriate for a key that represents a year?
A. Text
B. IntWritable
C. NullWritable
D. BytesWritable
E. None of these would be appropriate. You would need to implement a custom key.
Subscribe to:
Posts (Atom)